Ceph - Look around the CRUSH Map
CRUSH is the powerful, highly configurable algorithm Red Hat Ceph Storage uses to determine how data is stored across the many servers in a cluster.
A healthy Ceph Storage deployment depends on a properly configured CRUSH map.
For this blog post, I will review the Red Hat Ceph Storage architecture and explain the purpose of CRUSH.
Using example CRUSH maps, we will show you what works and what does not, and explain why.
About Ceph and Crush
Whether you want to provide an Object Storage and/or a Block Device to your OpenStack or Cloud platforms, deploy a distributed Filesystem, all these needs can be provide and manage by a Ceph Storage Cluster.
It requires at least one Ceph Monitor and at least two Ceph OSD Daemons and the Ceph Metadata Server is essential when running Ceph Filesystem clients.
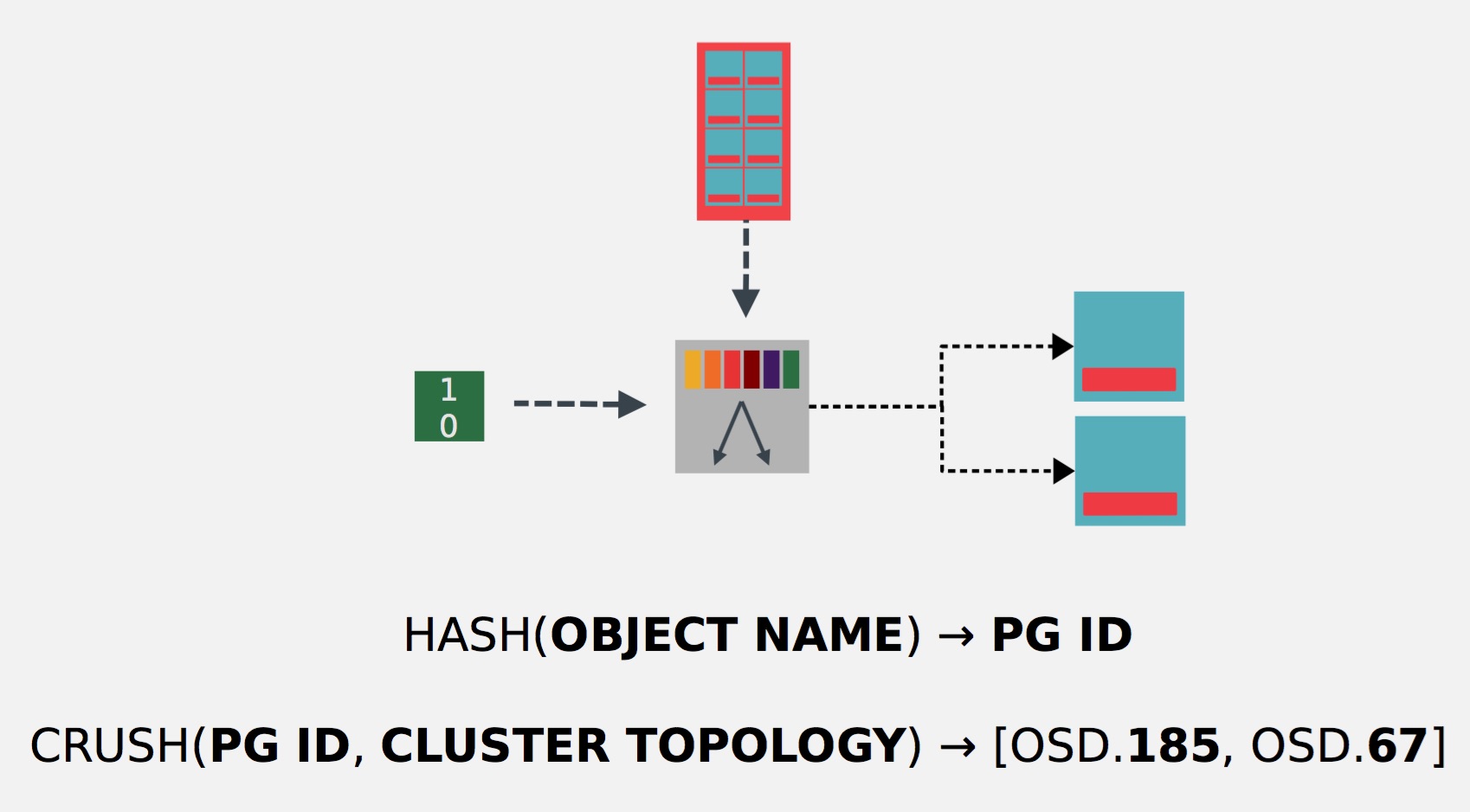
Ceph stores a client’s data as objects within storage pools. Using the CRUSH algorithm, Ceph calculates which placement group should contain the object, and further calculates which Ceph OSD Daemon should store the placement group.
The CRUSH algorithm enables the Ceph Storage Cluster to scale, rebalance, and recover dynamically.
Each object corresponds to a file in a filesystem, which is stored on an Object Storage Device. Ceph OSD Daemons handle the read/write operations on the storage disks.
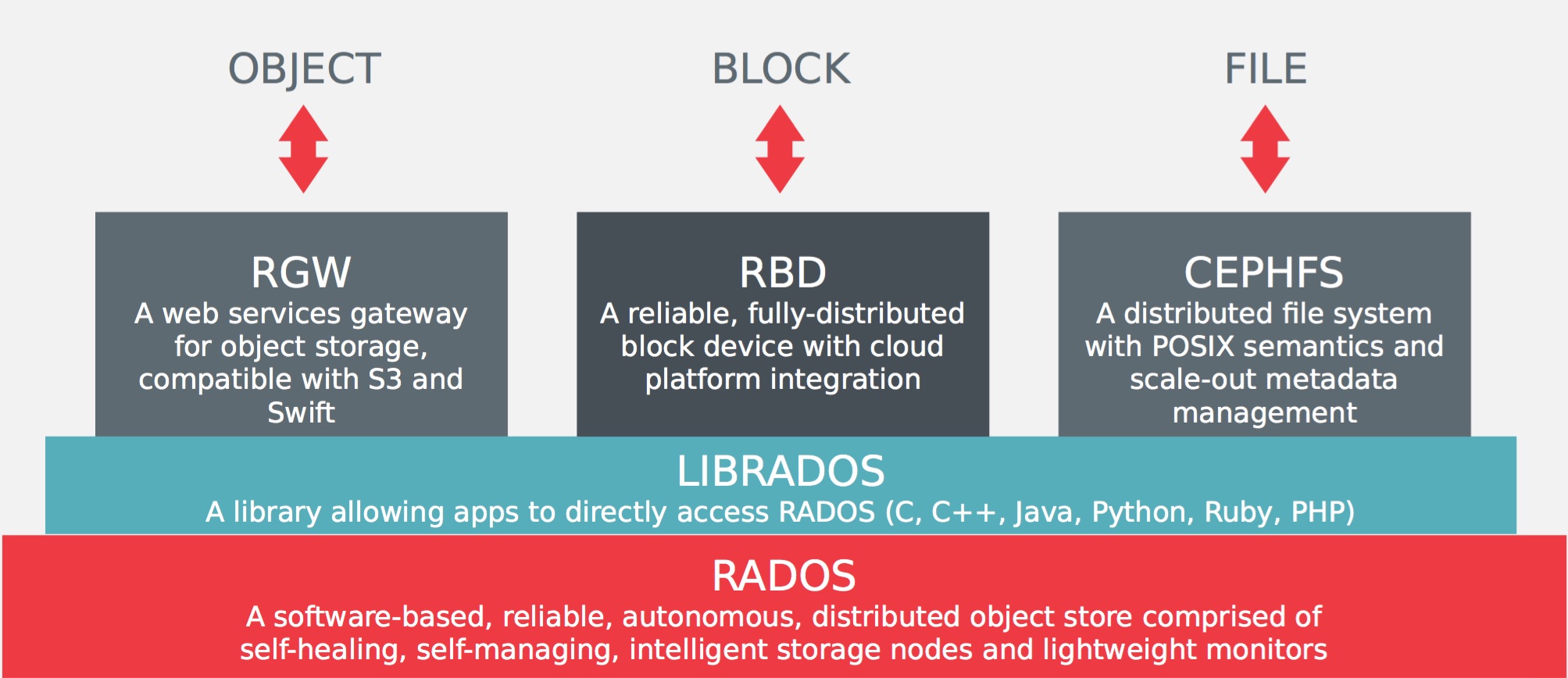
The Ceph Storage Cluster receives data from Ceph Clients–whether it comes through a Ceph Object Storage, Ceph Block Device or the Ceph Filesystem using librados – and it stores the data as objects.
Data Placement
Ceph stores, replicates and rebalances data objects across a RADOS cluster dynamically. With many different users storing objects in different pools for different purposes on countless OSDs, Ceph operations require some data placement planning.
Ceph use three planning concepts for the data placement:
- Pools: Ceph stores data within pools, which are logical groups for storing objects. Pools manage the number of placement groups, the number of replicas, and the ruleset for the pool.
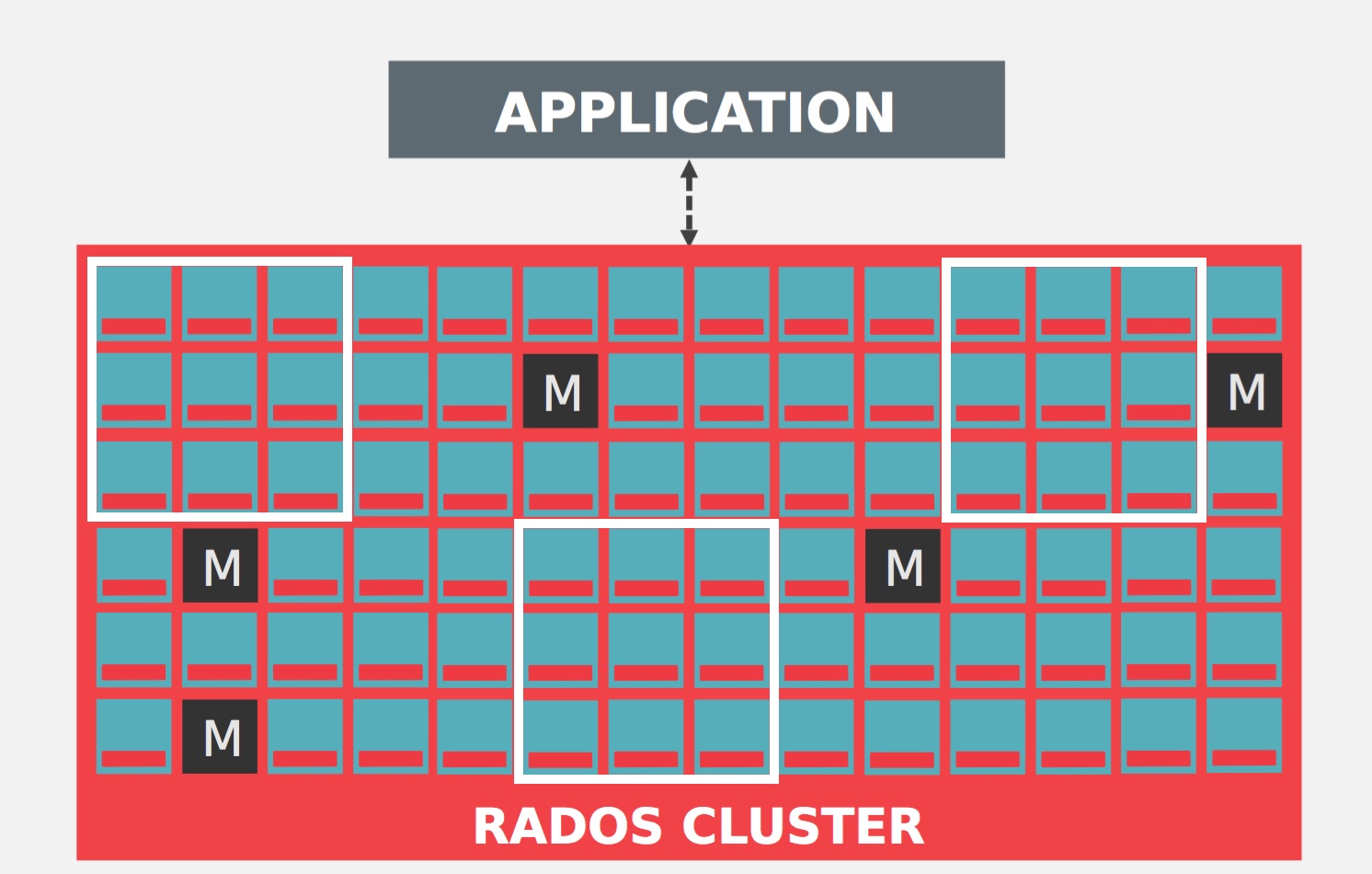
Pools are represented by white square. You can set how many OSD are allowed to fail without losing data, number of copies/replicas of an object or set the number of placement groups for the pool for example.
- Placement Groups: Placement groups (PGs) are shards or fragments of a logical object pool that place objects as a group into OSDs. Placement groups reduce the amount of per-object metadata when Ceph stores the data in OSDs. A larger number of placement groups (e.g., 100 per OSD) leads to better balancing.

A placement group (PG) aggregates objects within a pool because tracking object placement and object metadata on a per-object basis is computationally expensive Example: a system with millions of objects cannot realistically track placement on a per-object basis.
- CRUSH Map: CRUSH is a big part of what allows Ceph to scale without performance bottlenecks, without limitations to scalability, and without a single point of failure. CRUSH maps provide the physical topology of the cluster to the CRUSH algorithm to determine where the data for an object and its replicas should be stored, and how to do so across failure domains for added data safety among other things.
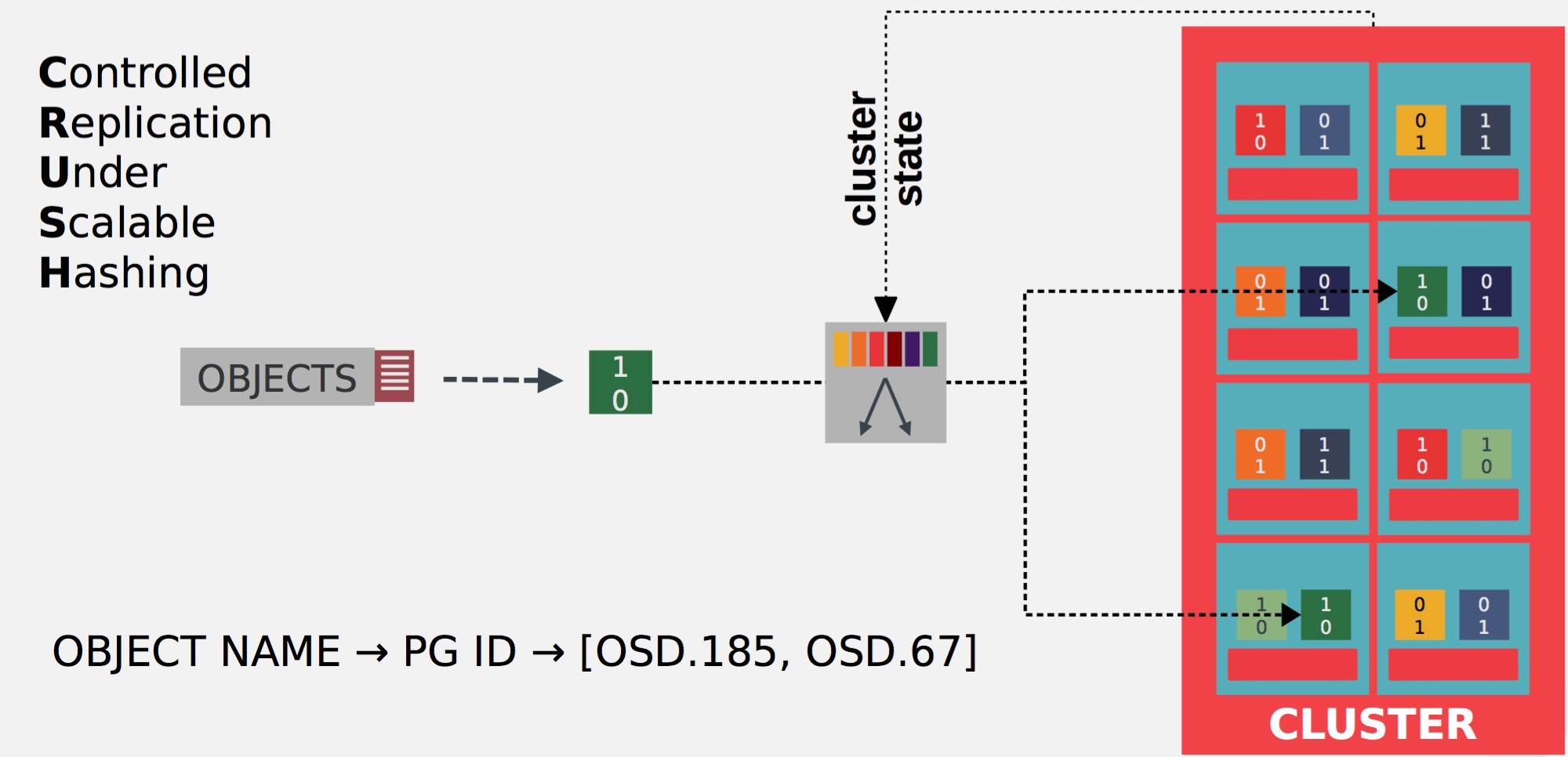
The CRUSH algorithm determines how to store and retrieve data by computing data storage locations. CRUSH empowers Ceph clients to communicate with OSDs directly rather than through a centralized server or broker.
Let’s now have a look on the Crush Map and how it works.
Crush Algorithm Overview
The CRUSH algorithm distributes data objects among storage devices according to a per-device weight value, approximating a uniform probability distribution.
The distribution is controlled by a hierarchical cluster map representing the available storage resources and composed of the logical elements from which it is built.
Example: one might describe a large installation in terms of rows of server cabinets, cabinets filled with disk shelves, and shelves filled with storage devices.
The data distribution policy is defined in terms of placement rules that specify how many replica targets are chosen from the cluster and what restrictions are imposed on replica placement.
Example: one might specify that three mirrored replicas are to be placed on devices in different physical cabinets so that they do not share the same electrical circuit.
Main advantages
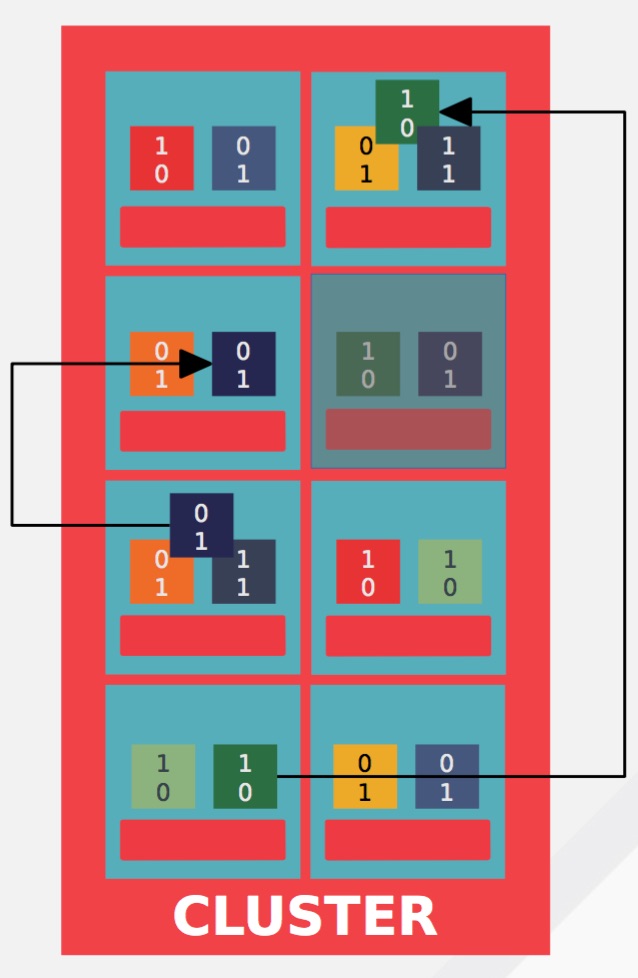
- Avoid failed devices: CRUSH take care of the data placement itself and can manage where to place object on the device.
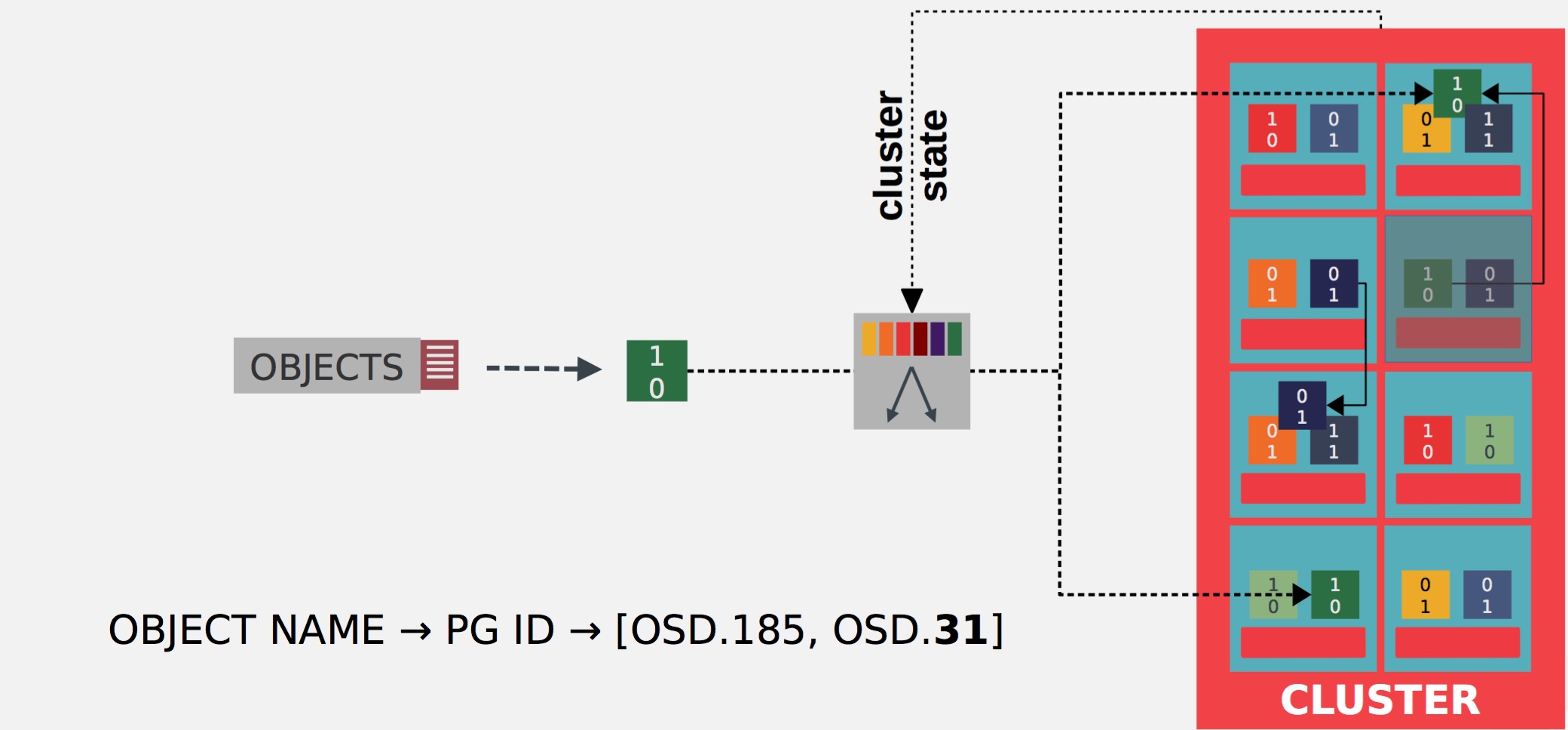
In this example, blue and green objects are relocate to others OSDs
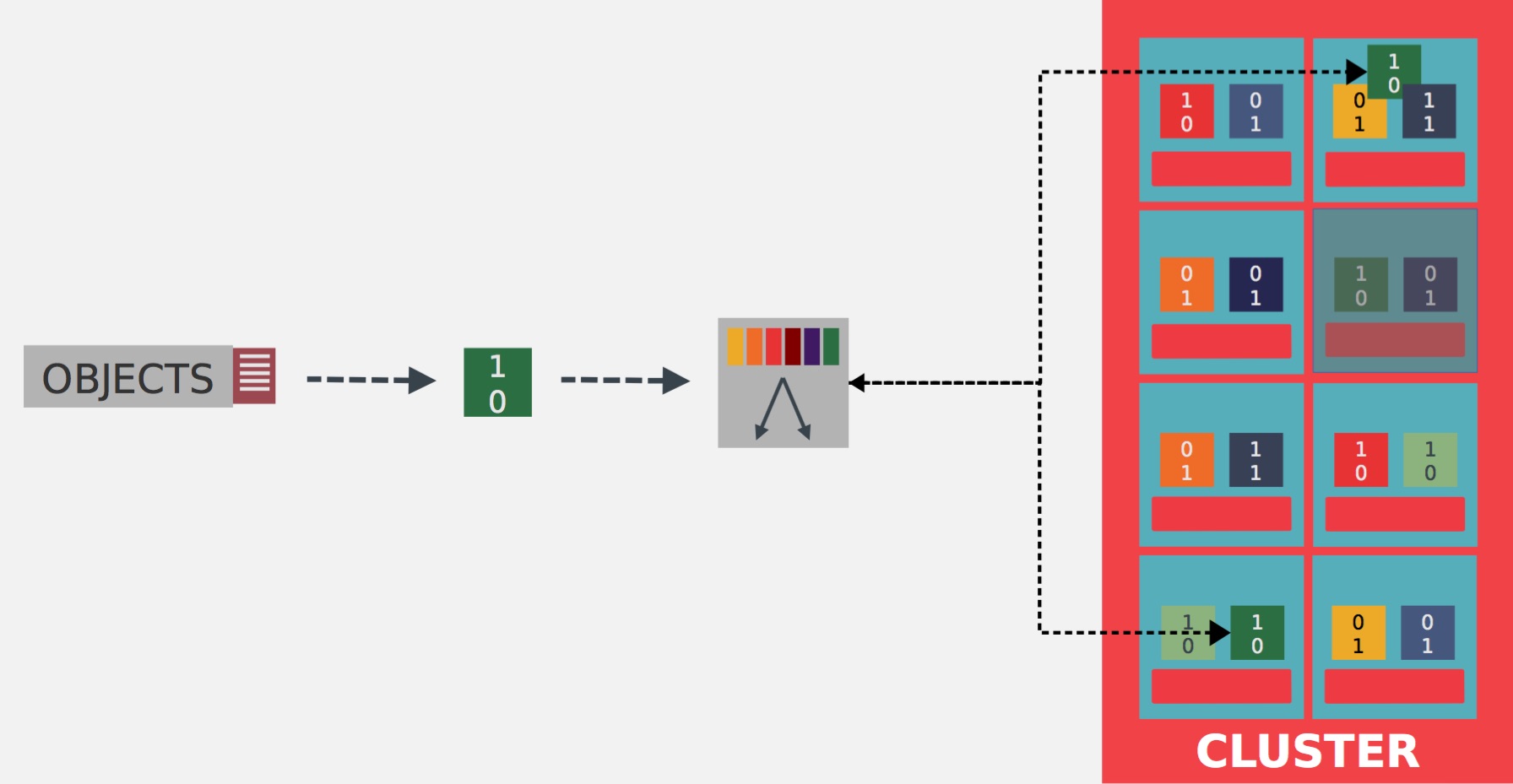
- Works as a function: CRUSH allows clients to communicate directly with storage devices without the need for a central index server to manage data object locations, Ceph clusters can store and retrieve data very quickly and scale up or down quite easily.
Fetching time are reduce with CRUSH, which allows direct communication from clients to storage devices
- Pseudo-random placement: CRUSH generates a declustered distribution of replicas in that the set of devices sharing replicas for one item also appears to be independent of all other items.
CRUSH’s separation of replicas across user-defined failure domains is specifically designed to prevent concurrent, correlated failures from causing data loss
- Device failures: Objects are replicated across multiple devices (or employ some other data redundancy scheme) in order to protect against data loss in the presence of failures.
CRUSH placement policies can separate object replicas across different failure domains while still maintaining the desired distribution.
Key CRUSH properties
- No Storage – only needs to know the cluster topology
- Fast – microseconds, even for very large clusters
- Stable – very little data movement when topology changes Reliable – placement is constrained by failure domains
- Flexible – replication, erasure codes, complex placement schemes
CRUSH Hierarchy
CRUSH maps contain a list of OSDs (Physical disk), a list of buckets for aggregating the devices into physical locations, and a list of rules that tell CRUSH how it should replicate data in a Ceph cluster’s pools.
Buckets can contain any number of OSDs or other buckets, allowing them to form interior nodes in a storage hierarchy in which devices are always at the leaves.
OSDs and buckets, both of which have numerical identifiers and weight values associated with them.
By reflecting the underlying physical organization of the installation, CRUSH
can model—and thereby address—potential sources of correlated device failures.
Typical sources include physical proximity, a shared power source, and a
shared network.
By encoding this information into the cluster map, CRUSH placement policies can separate object replicas across different failure domains while still maintaining the desired distribution.
For example, to address the possibility of concurrent failures, it may be desirable to ensure that data replicas are on devices using different shelves, racks, power supplies, controllers, and/or physical locations.

Example of a hierarchical CRUSH
Key Failover properties
- CRUSH generates n distinct devices (OSDs): should be replicas or erasure coding shards
- Separate replicas across failure domains
- Single failure should only compromise one replica
- Size of failure domain depends on cluster size (Disk, Host, Rack and Row)
- Based on types in CRUSH hierarchy
- Sources of failure should be aligned: per-rack switch and PDU and physical location
CRUSH Rules
CRUSH maps support the notion of ‘CRUSH rules’, which are the rules that determine data placement for a pool.
For large clusters, you will likely create many pools where each pool may have its own CRUSH ruleset and rules.
CRUSH rules defines placement and replication strategies or distribution policies that allow you to specify exactly how CRUSH places object replicas.
The default CRUSH map has a rule for each pool, and one ruleset assigned to each of the default pools.
Example:
rule flat {
ruleset 0
type replicated
min_size 1
max_size 10
step take root
step choose firstn 0 type osd
step emit
}More informations: CRUSH Maps — Ceph Documentation
